Devlog #4 - Training My Drone: Target Collection Basics
The goal of the agent is to navigate toward a target. If the agent successfully reached the target, it received a positive reward of +5. However, if it collided with the boundaries of the environment, it was penalised with a negative reward of -20.
This reward setup created a strong incentive for the agent to:
- Seek out the target.
- Learn how to move efficiently and safely.
- Avoid reckless behaviour.
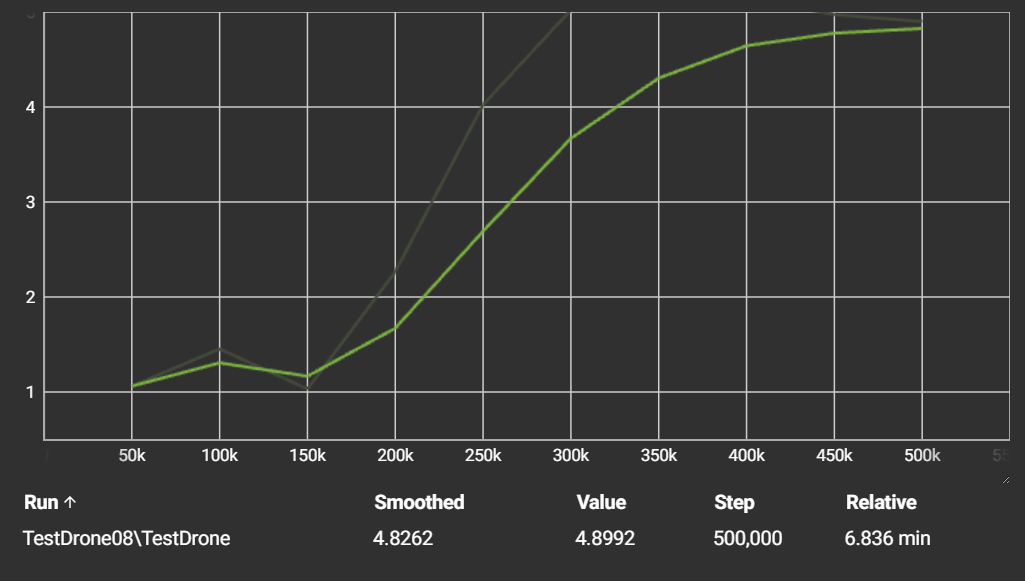
The Reward Graph: What It Tells Us
Below is a screenshot of the reward curve generated using TensorBoard, a visualisation tool for machine learning metrics. This chart is key to understanding how well the agent learned over time.
Key Elements:
- X-axis (Step): Represents the number of training steps taken, in this case, 500,000.
- Y-axis (Value): Shows the average reward the agent received per episode.
- Smoothed Line: The green line reflects a moving average to help visualise the trend.
What Happened During Training?
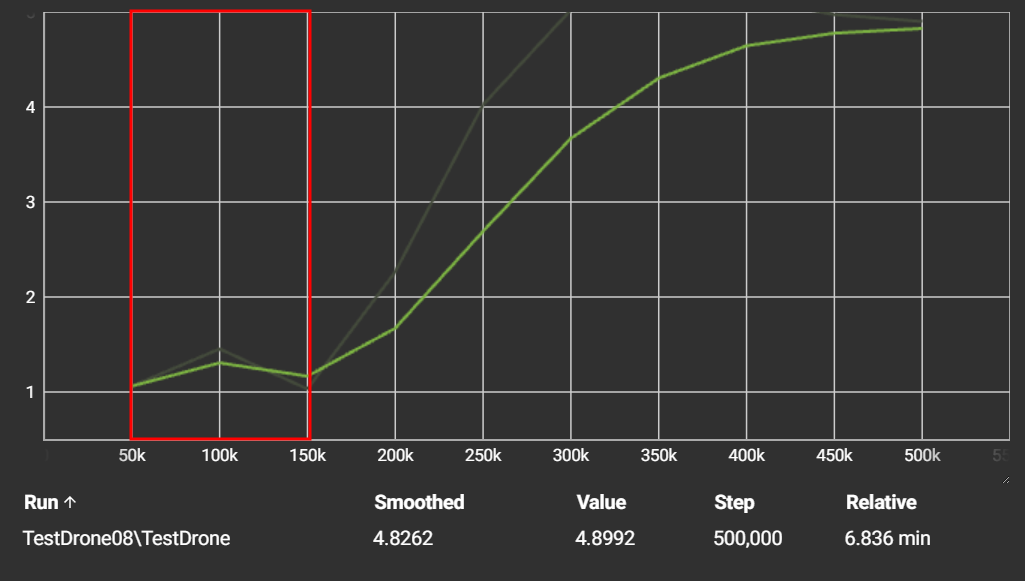
1. Exploration Phase (50k - 150k steps):
Initially, the agent's performance was modest. The average reward hovered around 1.0 to 1.5, indicating that the drone was:
- occasionally reached the target
- but frequently hit the boundaries.
This is typical in the early stages of reinforcement learning, as the agent is still exploring the environment and has no prior knowledge of how to succeed.
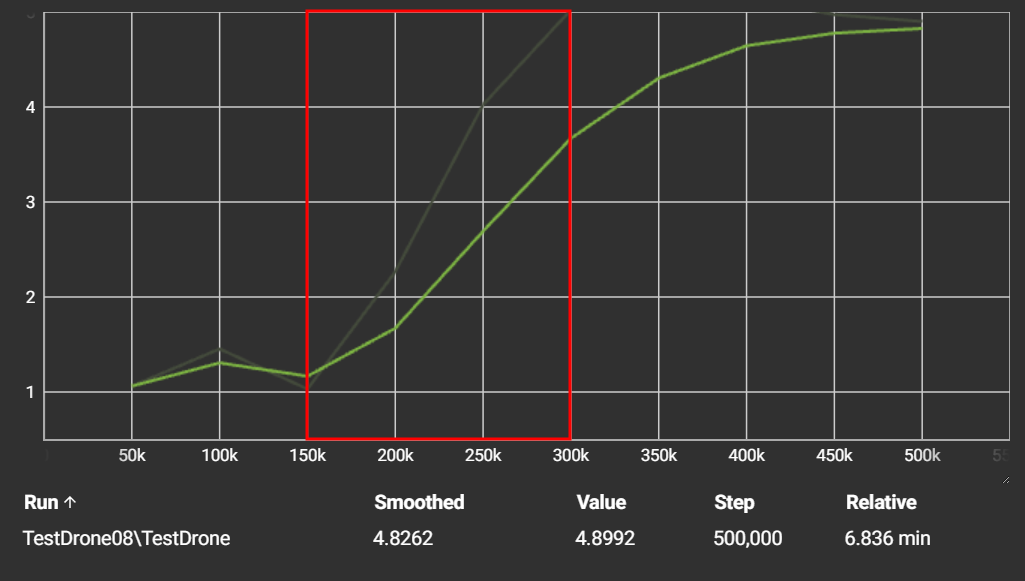
2. Learning Phase (150k - 300k steps):
In this phase, the reward begins to increase, indicating that the agent is:
- Learning which actions lead to rewards.
- Avoiding boundaries more effectively.
- Navigating more directly toward the target.
This steep upward trend shows that the agent is starting to develop a policy, a strategy that maximises its expected reward.
3. Stabilisation Phase (300k - 500k steps):
By the time the training reaches 500,00 steps, the average stabilises at around 4.9. This is significant because:
- It's very close to the maximum possible reward per episode (5.0).
- It suggests that the agent has learned a near-optimal policy: collect the target consistently while avoiding mistakes.
This is a good sign; it shows that the agent is no longer just exploring but is now exploiting a well-learned behaviour.
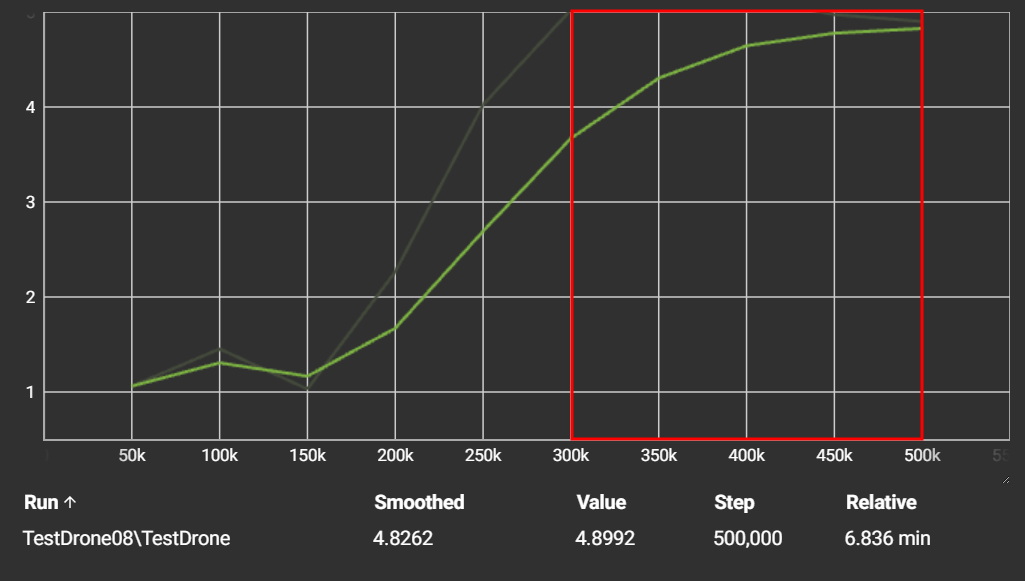
This training run demonstrates a successful application of reinforcement learning using Unity ML-Agents. The agent started with random behaviour and ended up with a highly effective strategy through trial, error and learning from feedback.
Applying the Trained Model to the Agent
After successfully training the model, the next step is to integrate it into the agent for real-time decision making. In this phase, I changed the behaviour type to "Inference Only". This allows the agent to use the learned knowledge to predict or act in new situations without any further learning.
The ML-Agents training process outputs a neural network in the ONNX format, typically located in a results folder.
Switching to Inference Mode
To begin, I changed the agent's Behaviour Type from Default to "Inference Only". This is a crucial step, as it ensures that the agent is no longer exploring or learning, but instead relies entirely on the trained mode to make decisions.
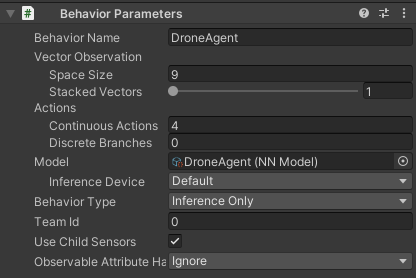
Behaviour Type: Inference Only This tells the agent to act based soley on the trained policy stored in the .onnx file.
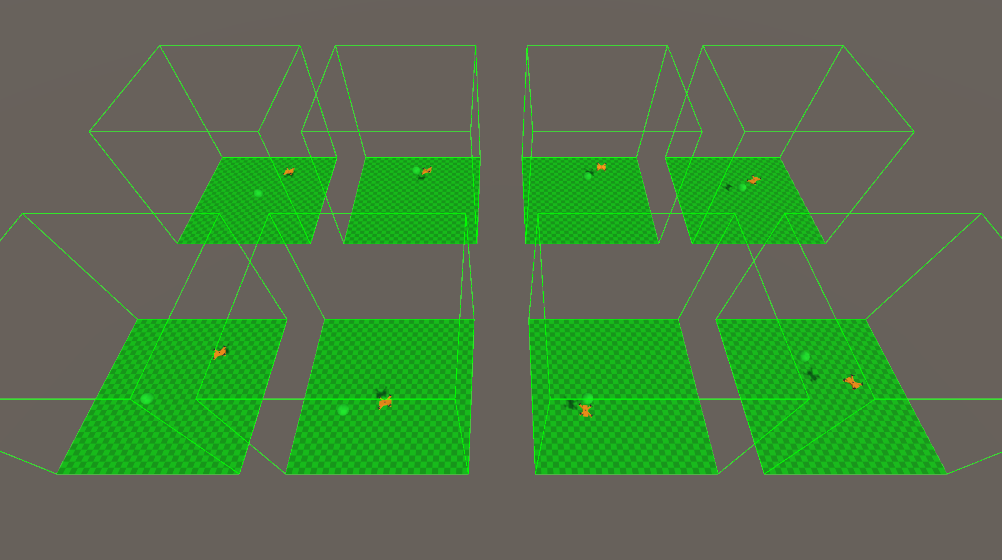
Agent in Action
Once deployed, the agent began navigating toward the target without any further training.
Below are some snapshots of the agent in motion:

- The drone actively avoids walls and heads straight for the target.

- The green rays represent the agent's perception (e.g. raycasts to detect tags such as obstacles and targets).
Next Steps
With a solid foundation in place and a trained agent successfully navigating to targets, I'm taking the project a step further in my next phase.
What's Coming Next:
- Expanded Training Environment
The original environment was relatively small and simple. In the next phase, I will introduce a larger environment to test the agent's ability to generalise its behaviour.
- Battery Mechanic
I will add a battery system to simulate energy usage. The drone will have to:
- Balance goal-seeking with resource conservation.
- Recharge at a charging station.
- Make more strategic decisions on when to charge/find targets.
Leave a comment
Log in with itch.io to leave a comment.