Devlog #6 - Training My Drone: Custom PPO Configuration
Before I started building a custom PPO configuration, I ran into a wall.
I had just expanded the drone's environment, adding a battery system, a charging station, and increasing the environment size. It seemed like everything was in place. The agent could fly, detect objects, track its battery and even earn shaped rewards based on behaviour.
But when trained, it learnt poorly and inconsistently.
What Went Wrong?
I was still using the default PPO configuration that comes with Unity ML-Agents. While it works for simple environments, my updated setup was now too complex. Here's what I observed during training:
- The agent would just wander randomly without reaching the target or the charging station.
- Rewards were rare or chaotic; sometimes the drone got lucky, but never reliably.
- Even after thousands of steps, there was no sign of consistent improvement.
This is a classic case of underpowered training settings for a task that needs more exploration, stability, and feedback.
The Fix: Building a Custom PPO Config
First, I downloaded a template YAML file [1] from the Coder One website. This is a good starting point, as now I can just tweak the parameters that will help my agent learn better. I reviewed the ML Agents documentation [2] for the description of the configurations. This helped me learn what settings I should change to improve the agents' learning.
Using the template, I started tweaking and adding the following:
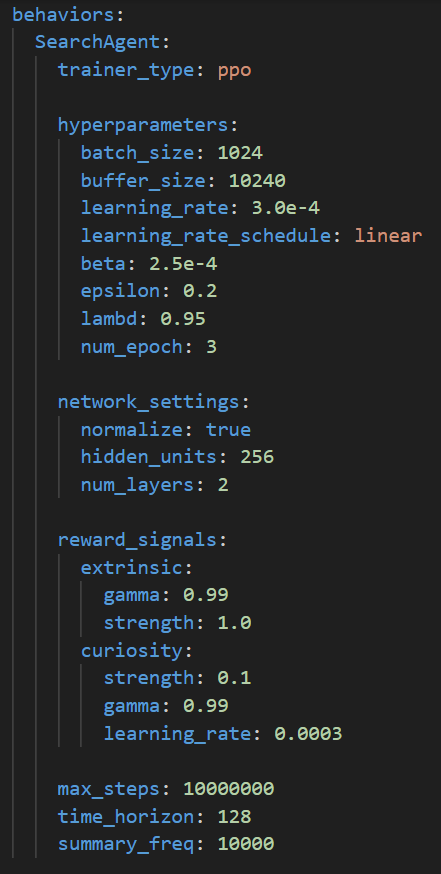
- Increased the buffer and batch size to help the agent collect and learn from more diverse experiences.
hyperparameters:
batch_size: 1024
buffer_size: 10240
- Adjusted the learning rate and added a linear schedule to stabilise training over time.
hyperparameters:
learning_rate: 3.0e-4
learning_rate_schedule: linear
- Tweaked entropy (beta) and clipping (epsilon) to balance exploration and stable learning,
hyperparameters:
beta: 2.5e-4
epsilon: 0.2
- Enabled the curiosity module to encourage exploration, especially since rewards are sparse early in training.
reward_signals:
curiosity:
strength: 0.1
gamma: 0.99
learning_rate: 0.0003
- Rebuilt the neural network size to better handle the richer observation space.
network_settings:
normalize: true
hidden_units: 256
num_layers: 2
- Increased the number of max steps to 10,000,000 to give it more time to train. I also changed the summary frequency to every 10,000 steps, as it helps me monitor performance quicker.
max_steps: 10000000 time_horizon: 128 summary_freq: 10000
What I Learned
Training an agent for a more complex world requires more thoughtful training. The default PPO setup is a good starting point, but it isn't as effective for bigger environments. Creating a custom config gives me more control and better results, especially as I add more interactivity to the environment.
References
[1] https://www.gocoder.one/blog/training-agents-using-ppo-with-unity-ml-agents/
[2] https://github.com/Unity-Technologies/ml-agents/blob/release_18_docs/docs/Traini...
Leave a comment
Log in with itch.io to leave a comment.